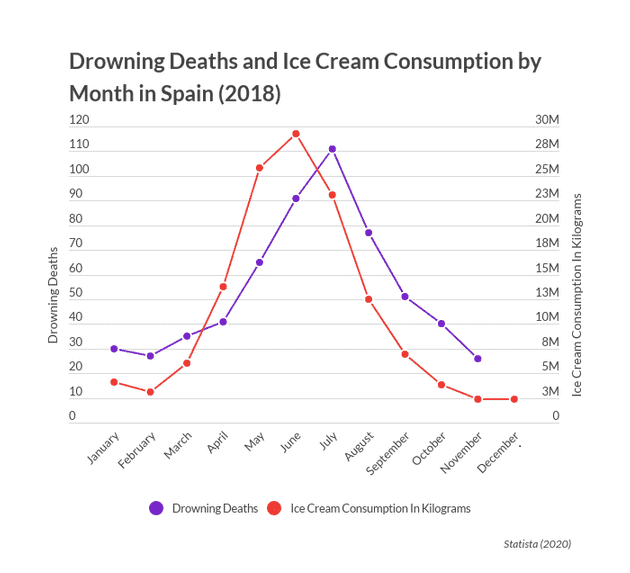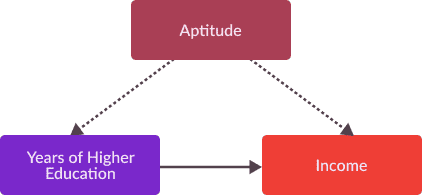
Surrogate Indicies
February 04, 2021How can we estimate the effects of policies which impact individuals over a long time period.
A casual introduction to causal inference for business analytics, by Ken Acquah
How can we estimate the effects of policies which impact individuals over a long time period.
Analysts are often interested how a particular intervention differentially affects individuals within an observed population, given high dimensional data describing each individual's characteristics. In this scenario, what state of the art machine learning technique is best suited for estimating heterogeneous treatment effects?
Oftentimes, analysts are interested how a particular intervention differentially affects an observed population. Exposure to a particular advertisement, experimental drug, or economic policy might affect different consumers in different ways. How can we estimate causal effects which vary across a population?
What are some of the challenges an analyst must be wary of when using propensity score matching for causal inference tasks?
How can an analyst 'control' for a large number of confounding variables when they are analyzing causal effects in an observational setting, and have very little control over which individuals receive which treatment?
So far, our discussions of causality have been rather straightforward: we've defined models for describing the world and analyzed their implications. In this post I present the obstacles we may face when leveraging these models as well as the 'adjustments' we can make to remove them.
When quantifying the causal effect of a proposed intervention, we wish to estimate the average causal effect this intervention will have on individuals in our dataset. How can we estimate average treatment effects and what biases must we be wary of when evaluating our estimation?
We’ve defined a language for describing the existing causal relationships between the many interconnected process that make up our universe. Is there a way we describe the extent of these relationships, in order to more wholly characterize causal effects?
How do we represent causal relationships between the many interconnected processes which comprise our universe?
What is causal inference? Why is it useful? How can you use to amplify your decision-making capabilities?